© 2021 Mullins Consulting, Inc. All Rights Reserved Privacy Policy Contact Us




Architectures for Clustering: Shared Nothing and Shared Disk
by Craig S. Mullins
Quarter 1, 2003
An e-
So e-
Many organizations turn to clustering as they look to increase the availability and computing capabilities of their hardware. Clustering basically works on the principle that multiple processors can tackle a problem better, faster, and more reliably than a single computer. That concept seems easy enough to grasp.
But, for many companies considering clustering options, the devil is in the details. How should clustering be accomplished? What technologies and architectures provide the best approach to clustering? I’ll get to those answers after exploring the concept of clustering in more detail.
Why Use Clusters?
Companies generally turn to clustering to improve availability and scalability. Clusters improve availability by providing alternate options in case a system fails. As I mentioned, clustering involves multiple, independent computing systems working together as one. So, if one of the independent systems fails, the cluster software can distribute work from the failing system to the remaining systems in the cluster. Users won’t know the difference – they interact with a cluster as though it were a single server – and the resources they rely on will still be available.
Most companies consider enhanced availability the primary benefit of clustering. In some cases, clustering can help companies achieve “five nines” (99.999 percent) availability.
But clustering offers scalability benefits, too. When load exceeds the capabilities of the systems that make up the cluster, you can incrementally add more system to increase the cluster’s computing power and meet processing requirements. As traffic or availability assurance increases, all or some parts of the cluster can be increased in size or number.
Available since it was introduced by DEC for VMS systems in the 1980s, clustering packages are now offered by major hardware and software companies including IBM, Microsoft, Sun Microsystems.
DB2
Magazine
Types of Clustering
Shared-
In a shared-
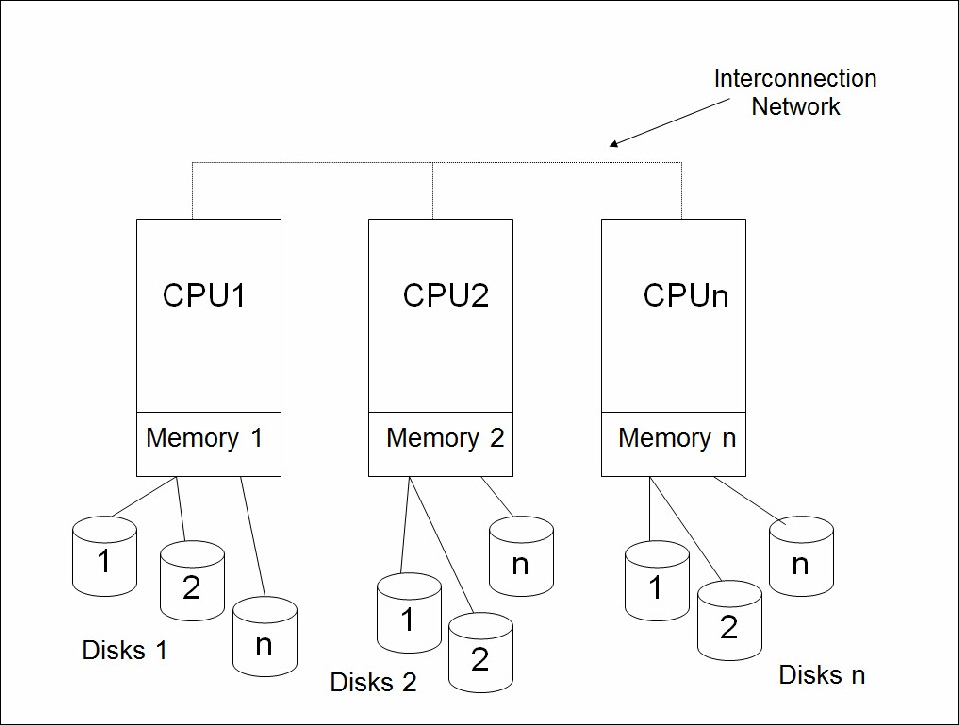
Figure 1. The shared-
Shared-
In a shared-
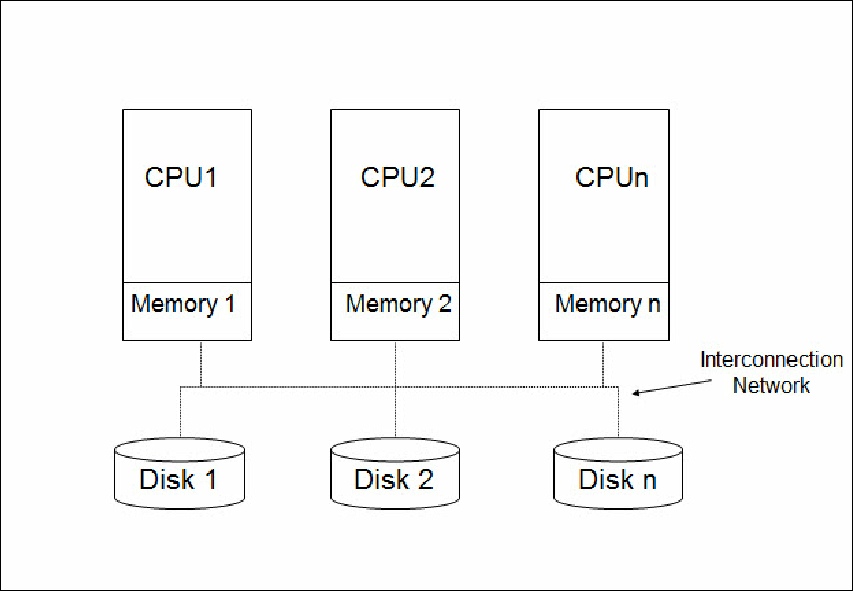
Figure 2. The shared-
Typically, shared-
The specialized technology and software of the Parallel Sysplex capability of IBM’s mainframe family makes shared-
Shared disk usually is viable for applications and services requiring only modest shared access to data as well as applications or workloads that are very difficult to partition Applications with heavy data update requirements probably are better implemented as shared-
|
Shared- |
Shared- |
|
Quick adaptability to changing workloads |
Can exploit simpler, cheaper hardware |
|
High availability |
Almost unlimited scalability |
|
Performs best in a heavy read environment (for example, a data warehouse) |
Works well in a high- |
|
Data need not be partitioned |
Data is partitioned across the cluster |
Table 1. Shared-
IBM offers both a shared-
No Sharing: DB2 UDB EEE
DB2 Universal Database (UDB) Enterprise-
With shared-
Sidebar: SMP
SMP is an acronym for Symmetric Multiprocessing. SMP is an architecture that takes advantage of multiple CPUs to complete individual processes simultaneously (multiprocessing). With SMP any idle processor can be assigned any task, and additional CPUs can be added to improve performance and handle increased loads. Each individual application can benefit from SMP if its code allows multithreading.
To configure DB2 EEE to execute in a shared-
This clustering enables customers to run applications on more than one node for increased scalability and high availability. DB2 UDB EEE supports a diverse set of hardware options including SMP, NUMA servers, and pSeries (RS/6000) clusters with a range of interconnect options. DB2 exploits AIX HACMP (High Availability Cluster Multiprocessing) features on RS/6000 processors (refer to Sidebar: HACMP for additional details). Further, DB2 UDB EEE can run on multiple operating systems including AIX, Linux, HP-
Sidebar: HACMP
IBM's High Availability Cluster Multi-
HACMP addresses the majority of situations that cause computer downtime. With HACMP/ES (for Enhanced Scalability) IBM takes the next step to make the cluster more aware of software failures. HACMP/ES can detect failures that are not severe enough to crash or hang the operating system, yet are severe enough to interrupt the proper system operations. With HACMP/ES the cluster can detect these problems so they can be corrected before causing a critical failure.
Applications accessing DB2 UDB EEE databases benefit from the robust, cost-
DB2 UDB EEE uses intelligent data distribution to distribute the data and database functions to multiple hosts. DB2 UDB EEE uses a hashing algorithm that enables it to manage the distribution (and redistribution) of data as required. Initially, the DBA must create the database objects to support partitions across the shared-
Data Sharing with DB2 for OS/390
Historically, larger organizations with multiple mainframes often installed individual processors for dedicated groups of users. But when DB2 applications needed to span the organization, DBAs had to create a duplicate copy of the application for each DB2 subsystem within the organization. So, IBM developed a system for data sharing for DB2 for OS/390 and Parallel Sysplex (a collection of MVS systems that communicate and exchange data with each other).
DB2 data sharing allows applications running on multiple DB2 subsystems to concurrently read and write to the same data sets concurrently. Simply stated, data sharing enables multiple DB2 subsystems to behave as one.
Data sharing requires a complex combination of hardware and software. To share data, DB2 subsystems must belong to a predefined data sharing group. Each DB2 subsystem that belongs to a particular data sharing group is a member of that group. All members of a data sharing group use the same shared DB2 catalog and directory. The maximum number of members in a data sharing group is 32 (though most data sharing implementations are far fewer in number).
Each data sharing group is an MVS Cross-
DB2 data sharing requires a Sysplex environment consisting of:
- At least one Sysplex timer, which keeps the processor timestamps synchronized for all DB2s in the data sharing group
- A connection to shared DASD, where user data, system catalog and directory data, and MVS catalog data all reside
- At least one coupling facility, a component that manages the shared resources of the connected central processor complexes (CPCs)
- One or more CPCs—consisting of main storage, central processors, timers, and channels—that can attach to a coupling facility.
Sidebar: Coupling Facility
DB2 uses the coupling facility to provide intermember communications. Coupling facility ensures data availability while maintaining data integrity across the connected DB2 subsystems. To do so, the coupling facility provides core services (such as data locking and buffering) to the data sharing group. The coupling facility uses three structures to synchronize the activities of the data sharing group members:
- Lock structures control global locking across the data sharing group members. Global locks are required because multiple members can access the same data, so each member needs to know the state of the data before it can be modified. The lock structure propagates locks to all members of the data sharing group.
- The list structure, also known as the Shared Communication Area (SCA), enables communication across the sysplex environment. The SCA maintains information about the state of databases, log files, and other details needed for DB2 recovery.
- Cache structures provide common buffering for the systems in the Sysplex. When a data page is updated by an individual data sharing member, a copy of that page is written to one of the global buffer pools. If other members need to refresh their copy of the data page, the copy is obtained from the coupling facility's global buffer pool instead of from disk. This requires the members to check the appropriate coupling facility global buffer pool first, to determine if the desired page needs to be read from disk or not.
In the long run, most organizations using DB2 for z/OS and OS/390 will implement data sharing instead of relying on a single mainframe, or several independent, unclustered mainframes. [Craig, rather than what? Relying on a single mainframe? Or is it possible to cluster without data sharing? OK -
As with most clustering technologies, the primary benefit is enhanced data availability. Data is available for direct access across multiple DB2 subsystems, and applications can be run on multiple smaller, more competitively priced microprocessor-
An additional benefit is expanded capacity. Capacity is increased because more processors are available to execute the DB2 application programs. Instead of a single DB2 subsystem on a single logical partition, multiple CPCs can be used to execute a program (or even a single query).
Data sharing increases the flexibility of configuring DB2. New members can be added to a data sharing group when it is necessary to increase the processing capacity of the group (for example, at month end or year end to handle additional processing). The individual members that were added to increase the processing capacity of the data sharing group are easily removed when it is determined that the additional capacity is no longer required.
No special programming is required for applications to access data in a DB2 data sharing environment. Each individual subsystem in the data sharing group uses the coupling facility to communicate with the other subsystems. The inter-
Summary
Shared-
IBM provides wide and deep support for clustering in its various incarnations of DB2. The shared-
From DB2 Magazine, Q1 2002.
© 2012 Craig S. Mullins,
Resources
DB2 UDB EEE clustering
IBM Redbook Managing VLDB Using DB2 UDB EEE (SG24-
www.redbooks.ibm.com
DB2 for OS/390 Data Sharing
IBM Redbook DB2 for MVS/ESA Version 4 Data Sharing Implementation (SG24-4791-00)
www.redbooks.ibm.com/