 Craig S. Mullins
Craig S. Mullins |
|
| October 1998 |
|
|
|

Referential Integrity in Microsoft SQL Server
Referential integrity is a method for ensuring the "correctness" of data within a DBMS. Many people tend to over-simplify RI stating that it is merely the identification of relationships between relational tables. It is actually much more than this. Of course, the identification of the primary and foreign keys that constitutes a relationship between tables is a component of defining referential integrity. RI appropriately embodies the integrity and usability of a relationship by establishing rules that govern that relationship. The combination of the primary and foreign key columns and the rules that dictate the data that can be housed in those columns is the very beginning of understanding and utilizing RI to ensure correct and useful relational databases. The set of RI rules, applied to each relationship, determines the status of foreign key columns when inserted or updated, and of dependent rows when a primary key row is deleted or updated. In general, a foreign key must always either contain a value within the domain of foreign key values (values currently in the primary key column), or be set to null. The concept of RI is summarized in the following "quick and dirty" definition: RI is a guarantee that an acceptable value is always in the foreign key column. Acceptable is defined in terms of an appropriate value as housed in the corresponding primary key, or a null. The combination of the relationship and the rules attached to that relationship is referred to as a referential constraint. The rules that accompany the RI definition are just as important as the relationship. Two other important RI terms are parent and child tables. For any given referential constraint, the parent table is the table that contains the primary key and the child table is the table that contains the foreign key. Examine Figure 1. The parent table in the employed-by relationship is the DEPT table. The child table is the EMP table. So the primary key (say DEPT-NO) resides in the DEPT table and a corresponding foreign key of the same data type and length, but not necessarily the with same column name, exists in the EMP table. 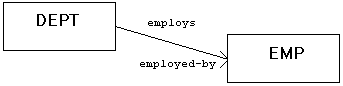 Figure 1. Parent and Child Tables. Theoretically, there are three types of rules that can be attached to each referential constraint: an insert rule, an update rule, and a delete rule. Let's see how these rules govern a referential constraint. Insert Rule The insert rule indicates what happens when attempting to insert a value into a foreign key column without a corresponding primary key value in the parent table. There are two aspects to the RI insert rule:
If a foreign key value is specified, it must be equal to one of the values currently in the primary key column of the parent table. This implements the RESTRICT insert rule. If a foreign key value is optional, it must be set to null. SQL Server's declarative RI supports both optional and required foreign key specification when a dependent row is to be inserted. Update Rule The basic purpose of the update rule is to control updates such that a foreign key value cannot be updated to a value that does not correspond to a primary key value in the parent table. There are, however, two perspective of the update rule: that of the foreign key and that of the primary key. Foreign Key Perspective Once a foreign key value has been assigned to a row, either at insertion or afterwards, it must be decided whether that value can be changed. Again, this is determined by looking at the business definition of the relationship and the tables it connects. However, if a foreign key value is permitted to be updated, the new value must either be equal to a primary key value currently in the parent table or be null. Primary Key Perspective If a primary key value is updated, three options exist for how to handle foreign key values:
Delete Rules Referential integrity rules for deletion define what happens when an attempt is made to delete a row from the parent table. Three options exist:
Declarative RI Constraints A declarative referential constraint is added by coding the primary key in the parent table and one or more foreign keys in dependent tables. Constraints can be added using the create table and alter table statements. When implementing declarative referential integrity between a parent and a dependent table, the following rules must be followed: For the parent table:
Declarative RI Implementation Concerns Microsoft SQL Server provides two methods of defining referential integrity: declarative constraints and triggers. Before deciding on whether to use declarative constraints or triggers to support referential integrity, careful examination of the integrity requirements of each referential constraint should be performed. For certain types of constraints, declarative RI will not be an option. Remember that declarative RI can be used to support only the RESTRICT rule. However, regardless of the type of RI being implemented, certain standard rules of thumb apply:
Triggers can be coded, in lieu of declarative RI, to support all of the RI rules. Of course, when you use triggers, it necessitates writing procedural code for each rule for each constraint. Complete referential integrity can be implemented using four types of triggers for each referential constraint:
In order to use triggers to support RI rules, it is sometimes necessary to know the values impacted by the action that fired the trigger. For example, consider the case where a trigger is fired because a row was deleted. The row, and all of its values, has already been deleted because the trigger is executed after its firing action occurs. But if this is the case, how can we ascertain if referentially-connected rows exist with those values? We may need to access it in its original, non-modified format. SQL Server provides two specialized tables with each trigger for just this purpose:
create trigger title_del on titles for delete as if @@rowcount = 0 return delete titleauthor from titleauthor, deleted, title where titles.title_id = deleted.title_id returnWhen a row in the parent table (titles) is deleted, the delete is cascaded to the dependent table (titleauthor). This code implements the cascading delete RI rule. Consider another example: create trigger title_ins on titleauthor for insert as declare @rc int select @rc = @@rowcount if @rc = 0 return if (select count(*) from titles, inserted where titles.title_id = inserted.title_id)!=@rc begin raiserror 20001 "Invalid title: title_id does not exist on titles table" rollback transaction return end returnThis code implements the restricted insert RI rule. When a row in the dependent table (titleauthor) is inserted, we must first check to see if a viable primary key exists in the parent table (titles). A final example depicts neutralizing updates: create trigger title_upd on titles for update as if update (title_id) if (select count(*) from deleted, titles where deleted.title_id = title.titleid) = 0 begin update titleauthor set titleauthor.titleid = NULL from titleauthor, deleted where titleauthor.titleid = deleted.title_id end returnThe first check is to see if the title_id was actually updated. Following that, the code checks to make sure that the title_id was not updated to the same value as it previously held. If it was, the neutralizing update should not occur. If these two checks are passed, the update occurs. When a row in the parent table (titles) is updated, we check to see if any corresponding rows exist in the dependent table (titleauthor). If so, the foreign key columns must be set to null. Trigger-Based RI Rules of Thumb
User- vs. System-Managed RI Since system-managed, declarative referential integrity has not always been an option with SQL Server, your installation may have applications with user-managed RI already in place. It may be necessary to support both user- and system-managed RI in this situation. Furthermore, even though system-managed RI is now available, sometimes user-managed RI is a more appropriate solution. One such instance is when it is always necessary for applications to access the parent and dependent tables (even when system-managed RI is implemented). For example, one application program always inserts the order row into the ORDR_TAB (parent) table before inserting the order item rows into the ORDR_ITEM_TAB (dependent) table and another application always accesses the rows in the ORDR_ITEM_TAB table for historical information before deleting them and then deleting the parent row from the ORDR_TAB table. Since these applications already access both tables, the additional overhead of system-implemented RI may not be worthwhile. However, the added benefit of system-managed RI is that the integrity of the data is also enforced during ad hoc access (interactive SQL, data warehouse queries, etc.). When RI is maintained only in programs, data integrity violations can occur if data modification is permitted outside the scope of the application programs that control RI. It is usually a wise move to implement system-managed referential integrity instead of user-managed. But remember, SQL Server provides two methods of implementing system-managed RI: declarative constraints and triggers. RI in Stored Procedures Referential integrity can also be coded into stored procedures. Using stored procedures enables the programmer to influence when the RI code will be executed. This can enhance overall performance. However, stored procedures are not generally recommended for supporting RI because:
Be aware that there are certain situations in which referential integrity can be bypassed. This can cause severe data integrity problems as well as significant confusion. The bcp utility can be used to load data into SQL Server tables without checking foreign key references. This makes the bcp load run faster because constraints are not checked. However, it also means that integrity problems will most likely exist. Another way to bypass RI is using the WITH NOCHECK clause when adding a foreign key to a table that already has data in it. Without the WITH NOCHECK clause SQL Server will automatically check all current data for constraint violations when adding the new foreign key. Using WITH NOCHECK, however, SQL Server will not check existing data; it will only check subsequent INSERT and UPDATE statements. A final way to bypass constraint checking is by altering the table with the clause NOCHECK CONSTRAINT. When the NOCHECK CONSTRAINT clause is specified no constraints defined for the table are checked. If there is a period of time when you do not want data integrity to be enforced you can alter the table to specify NOCHECK CONSTRAINT, and then when data integrity is to be automatically applied again alter the table back specifying CHECK CONSTRAINT. This method is not recommended because it inevitably results in data integrity problems that must be sought out and corrected later. General RI Rules of Thumb Regardless of the type of RI you plan to implement in your databases, there are several rules of thumb that should be heeded:
Microsoft SQL Server provides a wealth of features supporting referential integrity. Because one of the major problems plaguing production systems today is data quality, it is imperative that SQL Server DBAs understand, implement, and administer referential integrity in their database designs. Failure to do so can be a prescription for disaster.
© 1999 Mullins Consulting, Inc. All rights reserved.
|