© 2021 Mullins Consulting, Inc. All Rights Reserved Privacy Policy Contact Us




by Craig S. Mullins
If you are a SQL programmer, learning recursive SQL techniques can be a boon to your productivity. A recursive query is one that refers to itself. I think the best way to quickly grasp the concept of recursion is to think about a mirror that is reflected into another mirror and when you look into it you get never-
Different DBMS products implement recursive SQL in different ways. Recursion is implemented in standard SQL-
A CTE can be thought of as a named temporary table within a SQL statement that is retained for the duration of that statement. There can be many CTEs in a single SQL statement but each must have a unique name. A CTE is defined at the beginning of a query using the WITH clause.
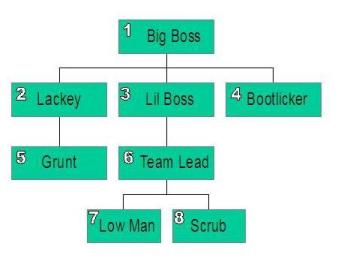
Now before we dive into recursion, let’s first look at some data that would benefit from being read recursively. Figure 1 shows a hierarchic organization chart.
A table holding this data could be
set up as follows:
CREATE TABLE ORG_CHART
(MGR_ID SMALLINT,
EMP_ID SMALLINT,
EMP_NAME CHAR(20)
);
Of course, this is a simple implemen-
Figure 1. A sample hierarchy
Table 1. Sample data
The MGR_ID for the top-
WITH EXPL (MGR_ID, EMP_ID, EMP_NAME) AS
(
SELECT ROOT.MGR_ID, ROOT.EMP_ID, ROOT.EMP_NAME
FROM ORG_CHART ROOT
WHERE ROOT.MGR_ID = 3
UNION ALL
SELECT CHILD.MGR_ID, CHILD.EMP_ID, CHILD.EMP_NAME
FROM EXPL PARENT, ORG_CHART CHILD
WHERE PARENT.EMP_ID = CHILD.MGR_ID
)
SELECT DISTINCT MGR_ID, EMP_ID, EMP_NAME
FROM EXPL
ORDER BY MGR_ID, EMP_ID;
The results of running this query would be as follows:
MGR_ID EMP_ID EMP_NAME
1 3 LIL BOSS
3 6 TEAM LEAD
6 7 LOW MAN
6 8 SCRUB
Let’s break this somewhat complex query down into its constituent pieces to help understand what is going on. First of all, a recursive query is implemented using the WITH clause (using a CTE). The CTE is named EXPL. The first SELECT primes the pump to initialize the “root” of the search. In our case, to start with EMP_ID 3, that is LIL BOSS.
The next SELECT is an inner join combining the CTE with the table upon which the CTE is based. This is where the recursion comes in. A portion of the CTE definition refers to itself. Finally, we SELECT from the CTE. Similar queries can be written to completely explode the hierarchy to retrieve all the descendants of any given node.
Recursive SQL can be very elegant and efficient. However, because of the difficulty developers can have understanding recursion, it is sometimes thought of as “too inefficient to use frequently.” But, if you have a business need to walk or explode hierarchies in your database, recursive SQL will likely be your most efficient option. What else are you going to do? You can create pre-
If every row processed by the query is required in the answer set (“find all employees who work for LIL BOSS”), then recursion will most likely be quite efficient. If only a few of the rows processed by the query are actually needed (“find all flights from Houston to Pittsburgh, but show only the three fastest”) then a recursive query can be quite costly. The bottom line is that you should consider recursive SQL when business requirements call for it. But be sure that suitable indexes are available and always examine your access paths.
Real-
As good as real-
ADVANCED ANALYTICS DEPLOYMENTS OFFER PRODUCTIVITY GAINS
The end result of deploying advanced analytics is increased productivity with the ability to gather and analyze large volumes of data to deliver faster, more-
Indeed, the whole big data phenomenon is largely focused on the analytical processing that is conducted on the data. But data need not be “big” in order to implement advanced analytics at your organization. And, ignoring the value that advanced analytics can provide your organization is not an option … because you can bet that your competition is not ignoring it!
From Database Trends and Applications, May 2014.
© 2014 Craig S. Mullins,
May 2014


|
MGR_ID |
EMP_ID |
EMP_NAME |
|
–1 |
1 |
BIG BOSS |
|
1 |
2 |
LACKEY |
|
1 |
3 |
LIL BOSS |
|
1 |
4 |
BOOTLICKER |
|
2 |
5 |
GRUNT |
|
3 |
6 |
TEAM LEAD |
|
6 |
7 |
LOW MAN |
|
6 |
8 |
SCRUB |