|
This article is adapted from the upcoming edition of Craig’s book, DB2 Developer’s Guide, 5th edition. This new edition, available now, updates the book to include coverage of DB2 Version 7 and Version 8. |
After using DB2 to store data or build applications, you should have a basic understanding of DB2 fundamentals. You are familiar with the functionality and nature of SQL, and you understand the process of embedding SQL in an application program and preparing it for execution. Additionally, you learned many tips and techniques for achieving proper performance.
But what is actually going on behind the scenes in DB2? When you create a table, how does DB2 create and store it? When you issue an SQL statement, what happens to it so that it returns your answer? Where are these application plans kept? What is going on “under the coversâ€? Let’s examine the answers to these questions.
The Physical Storage of Data
The first segment of your journey behind the scenes of DB2 consists of learning the manner in which DB2 data is physically stored. Before you proceed, however, recall the types of DB2 objects: STOGROUPs, databases, table spaces, tables, and indexes (refer to Figure 1). A database can be composed of many table spaces, which in turn can contain one or more tables, which in turn can have multiple indexes.
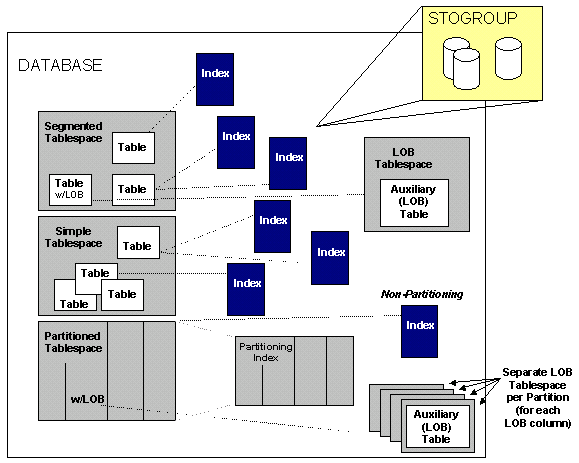
Figure 1: DB2 database objects.
Prior to DB2 V8, a partitioned table space required a partitioning index to set up the partition boundaries. As of DB2 V8, though, partition boundaries are set up in the table parameters, not the index. If an index exists on the partition keys, though, it is referred to as a partitioning index. Furthermore, DB2 V8 introduced DPSIs, or data partitioned secondary indexes. A DPSI is partitioned such that its data matches up with the table space partitions, even though the key of the index is not the partitioning key. Finally, a partitioned table space may have non-partitioned indexes, or NPIs. An NPI is neither partitioned, nor does its key match the partitioning key of the table space.
When LOB data types are used, LOB table spaces are required. In addition, databases, table spaces, and indexes can all be assigned STOGROUPs.
Of the five basic DB2 database objects, only three represent actual physical entities. STOGROUPs represent one or more physical disk devices. Table spaces and indexes relate to physical data sets. But tables and databases have no actual physical representation. A table is assigned to a table space, and one table space can have one or multiple tables assigned to it. Table spaces are created within a database; one database can have multiple table spaces. Any tables created in a table space in the database, and the indexes on that table, are said to be in the database. But the mere act of creating a database or creating a table does not create a physical manifestation in the form of a data set or disk usage.
Note: A DBD is created by DB2 when a database is created. The DBD is stored in the DB2 Directory and is managed in the EDM pool as database structures are accessed by users. The DBD contains the structure of the database objects in that database. It is used by DB2 to guide access to the objects stored in a database.
DB2 Physical Characteristics
There are a myriad of things that go on behind the scenes in DB2 as you create and access database structures. The following sections contain descriptions and guidelines regarding the physical implementation and control of DB2 objects.
The Identifiers: OBIDs, PSIDs, and DBIDs
When an object is created, DB2 assigns it an identifier that is stored in the DB2 Catalog. These identifiers are known as OBIDs. Furthermore, table spaces and index spaces are assigned PSIDs, otherwise known as page set IDs, because these objects require a physical data set. Databases are assigned DBIDs.
DB2 uses these identifiers behind the scenes to distinguish one DB2 object from another.
Storage Groups
You can assign up to 133 disk devices volumes to a single DB2 storage group. The practical limit, though, is far fewer. To ease administration and management, keep the number of volumes assigned to a STOGROUP to a dozen or so.
You can use a DB2 STOGROUP to turn over control to SMS. This is accomplished by specifying an asterisk as the volume when creating the DB2 storage group.
VSAM Data Sets
Data sets used by DB2 can be either VSAM entry-sequenced data sets (ESDS) or VSAM linear data sets (LDS). Linear data sets are more efficient because they do not contain the VSAM control interval information that an ESDS does. Additionally, an LDS has control intervals with a fixed length of 4,096 bytes.
Data Sets for Non-Partitioned Objects
Usually only one VSAM data set is used for each non-partitioning index, simple table space, and segmented table space defined to DB2. But, each data set can be no larger than 2 gigabytes. When the 2-gigabyte limit is reached, a new VSAM data set is allocated. DB2 can use as many as 32 VSAM data sets per object.
DB2 uses a specific data set naming standard for table space and index data sets, as follows:

The data set number is controlled by the last component of the data set name. For simple and segmented table spaces, the data set number is always preceded by A. The data set number for the first data set is always A001. When the size of the data set for a simple or a segmented table space approaches the maximum, another data set will be defined (for STOGROUP-controlled objects) with the data set number set to A002. For user-defined VSAM data sets, the DBA will have to allocate the data set using A002 as the data set number. The next data set will be A003, and so on.
Data Sets for Partitioned Objects
Multiple VSAM data sets are used for partitioned table spaces, partitioning indexes, and DPSIs. One data set is used per partition. For partitioned table spaces, the data set number is used to indicate the partition number.
The first character of the data set number, represented by the z will contain a letter from A through E. This letter corresponds to the value 0, 1, 2, 3, or 4 as the first digit of the partition number. Prior to DB2 V8, this character was the letter A. But now that Version 8 allows up to 4096 partitions, the letters A, B, C, D, and E must be used.
If the partition number is less than 1000, the data set number is Annn. For example, the data set number for partition 750 would be A750. For partitions 1000 to 1999, the data set number is Bnnn. For example, the data set number for partition 1025 would be B025. And so on. The same rules apply to the naming of data sets for partitioned indexes.
The maximum size of each data set is based on the number of defined partitions. If the partitioned table space is not defined with the LARGE parameter, and the DSSIZE is not greater than 2GB, the maximum number of partitions is 64 and the maximum size per partition is as follows:
|
Partitions |
Maximum Size of VSAM Data Set |
|
|
|
|
1 through 16 |
4GB |
|
17 through 32 |
2GB |
|
33 through 64 |
1GB |
Note: The DSSIZE parameter is used to specify the maximum size for each partition of partitioned and LOB table spaces. Valid DSSIZE values are 1GB, 2GB, 4GB, 8GB, 16GB, 32GB, or 64GB.
To specify a DSSIZE greater than 4GB, you must be running DB2 with DFSMS V1.5, and the data sets for the table space must be associated with a DFSMS data class defined with extended format and extended addressability. DFSMS’s extended addressability function is necessary to create data sets larger than 4GB in size.
If the partitioned table space is defined with the LARGE parameter, the maximum number of partitions is 4096 and the maximum size per partition is 4GB.
If the partitioned table space is defined with a DSSIZE greater than 2GB, the maximum size per partition is 64GB, but it depends on the page size, too. With a DSSIZE of 4GB and a page size of 4K you can define up to 4096 partitions. But with a DSSIZE of 64GB the maximum number of partitions using 4K pages is 256.
Data Sets for LOB Table Spaces
For LOB data, up to 127TB of data per LOB column can be stored (using 254 partitions). If DSSIZE is not specified for a LOB table space, the default for the maximum size of each data set is 4 GB. The maximum number of data sets is 254.
If 4096 partitions need to be supported, no more than 5 LOBs can be put in the table. This is so because each individual LOB would require 12,288 objects to support it, and DB2 has a limit of 65,535 objects allowed per database.
The Structure of a Page
Now that you know how data sets are used by DB2, the next question is likely to be “How are these data sets structured?â€
Every VSAM data set used to represent a DB2 table space or index is composed of pages. Up through V7, DB2 is limited to using pages consisting of 4,096 bytes, or 4KB. Actually, even for DB2 V8, the vast majority of all DB2 table spaces and indexes will use 4K pages.
But what about table spaces with larger page sizes? As you might know, DB2 table spaces can have page sizes of 4KB, 8KB, 16KB, or 32KB. Up through V7, DB2 groups 4KB pages together to create virtual page sizes greater than 4KB. For example, a table space defined with 32KB pages uses a logical 32KB page composed of eight physical 4KB pages. A table space with 32KB pages is physically structured like a table space with 4KB pages. It differs only in that rows of a 32KB page table space can span 4K pages, thereby creating a logical 32KB page.
As of DB2 V8, though, you can specify that DB2 use the correct CI size for DB2 page sizes greater than 4K. This is controlled system-wide using a parameter in the DSNZPARMs. Consult your DBA or system programmer to determine whether your organization uses grouped 4K pages for page sizes larger than 4K, or matches the page size to the VSAM CI size.
DB2 Page Types
DB2 uses different types of pages to manage data in data sets. Each type of page has its own purpose and format. The type of page used is based on the type of table space or index for which it exists and the location of the page in the data set defined for that object.
Before proceeding any further, I must introduce a new term, page set, which is a physical grouping of pages. Page sets come in two types: linear and partitioned. DB2 uses linear page sets for simple table spaces, segmented table spaces, and indexes. DB2 uses partitioned page sets when it implements partitioned table spaces.
Figure 2 shows the basic layout of a DB2 table space. Each page set is composed of several types of pages: header page, space map pages, dictionary pages, and data pages.
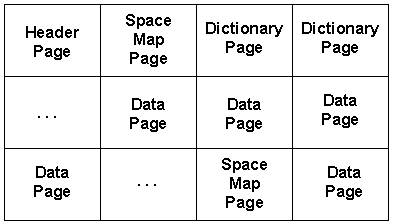
Figure 2: DB2 table space layout.
The header page contains control information used by DB2 to manage and maintain the table space. For example, the OBID and DBID (internal object and database identifiers used by DB2) of the table space and database are maintained here, as well as information on logging. Each linear page set has one header page; every partition of a partitioned page set has its own header page. The header page is the first page of a VSAM data set.
Space map pages contain information pertaining to the amount of free space available on pages in a page set. A space map page outlines the space available for a range of pages.
Dictionary pages are used for table spaces that specify COMPRESS YES. Information is stored in the dictionary pages to help DB2 control compression and decompression. The dictionary pages are stored after the header page and first space map page, but before any data pages.
Note: Each table space or table space partition that contains compressed data has a compression dictionary that is used to control compression and decompression. The dictionary contains a fixed number of entries, up to a maximum of 4096. The dictionary content is based on the data at the time it was built, and it does not change unless the dictionary is rebuilt or recovered, or compression is disabled using ALTER with COMPRESS NO.
Data pages contain the user data for the table space or index page set. The layout of a data page depends on whether it is an index data page or a table space data page.
Table space data pages
Each table space data page is formatted as shown in Figure 3. Each page begins with a 20-byte header that records control information about the rest of the page. For example, the header contains the page set page number, pointers to free space in the page, and information pertaining to the validity and recoverability of the page.
At the very end of the page is a 1-byte trailer used as a consistency check token. DB2 checks the value in the trailer byte against a single bit in the page header to ensure that the data page is sound.
The next-to-last byte of each page contains a pointer to the next available ID map entry. The ID map is a series of contiguous 2-byte row pointers. One row pointer exists for every data row in the table. A maximum of 255 of these pointers can be defined per data page. The maximum number of rows per page can be specified for each table space using the MAXROWS clause. Each row pointer identifies the location of a data row in the data page.
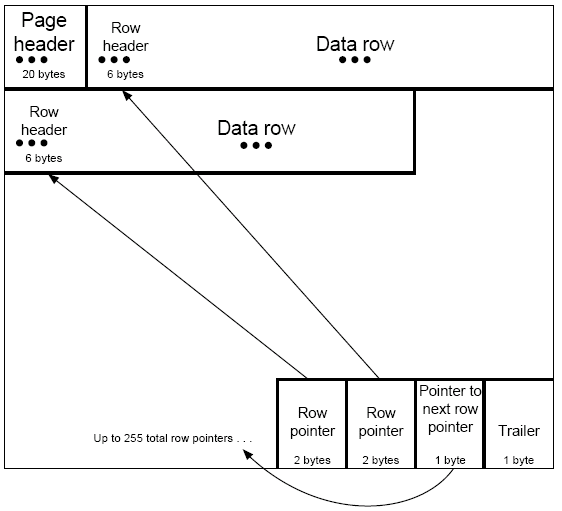
Figure 3: Table space data page layout.
Each data page can contain one or more data rows. One data row exists for each row pointer, thereby enforcing a maximum of 255 data rows per data page. Each data row contains a 6-byte row header used to administer the status of the data row.
LOB pages
LOB columns are stored in auxiliary tables, not with the primary data. An auxiliary table is stored in a LOB table space. The layout of data pages in a LOB table space differs from a regular DB2 table space. There are two types of LOB pages:
- LOB map pages
- LOB data pages
LOB map pages contain information describing the LOB data. A LOB map page always precedes the LOB data. Refer to Figure 4. There are potentially five components of the LOB map page.
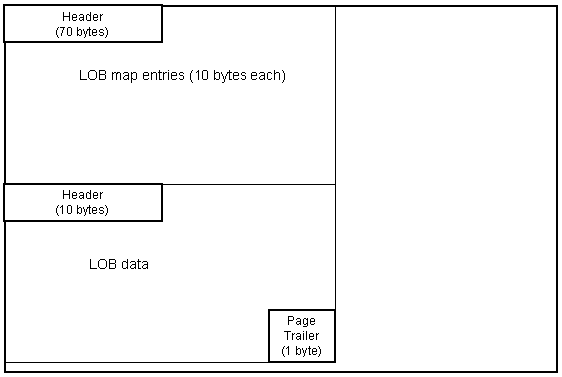
Figure 4: LOB map page layout.
The LOB map page header connects the LOB page with the base table. The LOB map entries point to the page number where LOB data exists, as well as containing information about the length of the LOB data.
The final two components of the LOB map page exist only when the LOB map page also contains LOB data. The LOB map page data header, LOB data, and page trailer exist when the last LOB map page contains LOB data. The LOB data page contains the actual LOB data. The layout of a LOB data page is depicted in Figure 5.
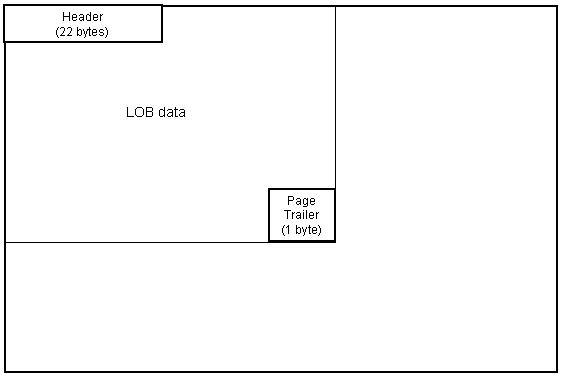
Figure 5: LOB data page layout.
Index pages
The data pages for a DB2 index are somewhat more complex than those for a DB2 table space. Before you delve into the specifics of the layout of index data pages, you should examine the basic structure of DB2 indexes.
A DB2 index is a modified b-tree (balanced tree) structure that orders data values for rapid retrieval. The values being indexed are stored in an inverted tree structure.
As values are inserted and deleted from the index, the tree structure is automatically balanced, realigning the hierarchy so that the path from top to bottom is uniform. This realignment minimizes the time required to access any given value by keeping the search paths as short as possible.
Every DB2 index resides in an index space. When an index is created, the physical space to hold the index data is automatically created if STOGROUPs are used. This physical structure is called the index space. Refer to Figure 6 for a depiction of the layout of an index space.

Figure 6: DB2 index space layout.
Index data pages are always 4KB in size. To implement indexes, DB2 uses the following types of index data pages:
|
Space map pages
|
Space map pages determine what space is available in the index for DB2 to utilize. An index space map page is required every 32,632 index pages. Figure 7 shows the layout of an index space map page. |
|
Root page
|
Only one root page is available per index. The third page in the index space, after the header page and (first) space map page, is the root page. The root page must exist at the highest level of the hierarchy for every index structure. It is always structured as a non-leaf page. |
|
Non-leaf pages
|
Non-leaf pages are intermediate-level index pages in the b-tree hierarchy. Non-leaf pages need not exist. If they do exist, they contain pointers to other non-leaf pages or leaf pages. They never point to data rows. |
|
Leaf pages |
Leaf pages contain the most important information within the index. Leaf pages contain pointers to the data rows of a table. |

Figure 7: Index space map page layout.
The pointers in the leaf pages of an index are called a record ID, or RID. Each RID is a combination of the table space page number and the row pointer for the data value, which together indicate the location of the data value.
Note: A RID is a record ID, not a row ID as is commonly assumed. A DB2 record is the combination of the record prefix and the row. Each record prefix is 6 bytes long. RIDs point to the record, not the row; therefore, a RID is a record ID. But don’t let this information change the way you think. The data returned by your SELECT statements are still rows.
The level of a DB2 index indicates whether it contains non-leaf pages. The smallest DB2 index is a two-level index. A two-level index does not contain non-leaf pages. The root page points directly to leaf pages, which in turn point to the rows containing the indexed data values.
A three-level index contains one level for the root page, another level for non-leaf pages, and a final level for leaf pages. The larger the number of levels for an index, the less efficient it will be. You can have any number of intermediate non-leaf page levels. The more levels that exist for the index, the less efficient the index becomes, because additional levels must be traversed to find the index key data on the leaf page. Try to minimize the number of levels in your DB2 indexes; when more than three levels exist, indexes generally start to become inefficient.
Type 1 Index Data Pages
Type 1 indexes are DB2’s legacy index type. These are the indexes that were available with DB2 since V1. They started to be called Type 1 indexes with the introduction of DB2 V4, which added a new type of index (Type 2 indexes).
As of V6, DB2 uses only Type 2 indexes. Type 1 indexes are no longer supported. Additionally, be aware that you will not be able to migrate to DB2 V8 if any Type 1 indexes still exist.
Type 2 Index Data Pages
Non-leaf pages are physically formatted as shown in Figure 8.

Figure 8: Type 2 index non-leaf page layout.
Each non-leaf page contains the following:
- A 12-byte index page header that houses consistency and recoverability information for the index.
- A 16-byte physical header that stores control information for the index page. For example, the physical header controls administrative housekeeping, such as the type of page (leaf or non-leaf), the location of the page in the index structure, and the ordering and size of the indexed values.
Each non-leaf page contains high keys with child page pointers. The last page pointer has no high key because it points to a child page that has entries greater than the highest high key in the parent.
Type 2 index non-leaf pages deploy suffix truncation to reduce data storage needs and increase efficiency. Suffix truncation allows a non-leaf page to store only the most significant bytes of the key. For example, consider an index in which a new value is being inserted. The value, ABCE0481, is to be placed on a new index page. The last key value on the previous page was ABCD0398. Only the significant bytes (ABCDE) needed to determine that this key is new need to be stored.
Entries on a Type 2 leaf page are not stored contiguously in order on the page. A collated key map exists at the end of the Type 2 leaf page to order the entries. Type 2 index leaf pages are formatted as shown in Figure 9. When an entry is added to the index, the collated key map grows backward from the end of the page into the page. By traversing the key map within the page, DB2 can read entries in order by the key.
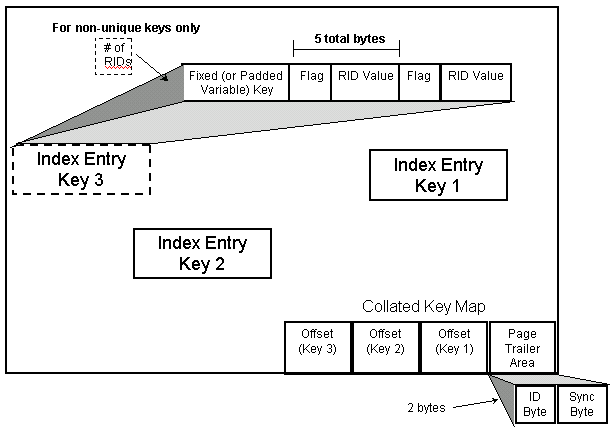
Figure 9: Type 2 Index leaf page layout.
Type 2 leaf page entries add a flag byte. The flag byte indicates the status of the RID. The first bit indicates whether the RID is pseudo-deleted. A pseudo-delete occurs when a RID has been marked for deletion. The second bit indicates that the RID is possibly uncommitted, and the third bit indicates that a RID hole follows. An array of RIDs is stored contiguously in ascending order to allow binary searching. For non-unique indexes, each index entry is preceded by a count of the number of RIDs.
The final physical index structure to explore is the index entry. You can create both unique and non-unique indexes for each DB2 table. When the index key is of varying length, DB2 pads the columns to their maximum length, making the index keys a fixed length. A unique index contains entries, and each entry has a single RID. In a unique index, no two index entries can have the same value because the values being indexed are unique (see Figure 10).

Figure 10: Index entries.
You can add the WHERE NOT NULL clause to a unique index causing multiple nulls to be stored. Therefore, an index specified as unique WHERE NOT NULL has multiple unique entries and possibly one non-unique entry for the nulls.
If the index can point to multiple table rows containing the same values, however, the index entry must support a RID list. In addition, a header is necessary to maintain the length of the RID list.
Record Identifiers
A RID is a 4-byte record identifier that contains record location information. RIDs are used to locate any piece of DB2 data. For large partitioned table spaces, the RID is a 5-byte record identifier.
The RID stores the page number and offset within the page where the data can be found. For pages in a partitioned table space, the high-order bits are used to identify the partition number.
Now that you know the physical structure of DB2 objects, you can explore the layout of DB2 itself.
What Makes DB2 Tick
Conceptually, DB2 is a relational database management system. Actually, some might object to this term instead calling DB2 a SQL DBMS because it does not conform exactly to Codd’s relational model.
Physically, DB2 is an amalgamation of address spaces and intersystem communication links that, when adequately tied together, provide the services of a database management system.
“What does all this information have to do with me?†you might wonder. Understanding the components of a piece of software helps you use that software more effectively. By understanding the physical layout of DB2, you can arrive at system solutions more quickly and develop SQL that performs better.
The information in this section is not very technical and does not delve into the bits and bytes of DB2. Instead, it presents the basic architecture of a DB2 subsystem and information about each subcomponent of that architecture.
Each DB2 subcomponent is comprised of smaller units called CSECTs. A CSECT performs a single logical function. Working together, a bunch of
CSECTs provide general, high level functionality for a subcomponent of DB2. DB2 CSECT names begin with the characters DSN.
There are three major subcomponents of DB2: system services (SSAS), database services (DBAS), and distributed data facility services (DDFS).
The SSAS, or System Services Address Space, coordinates the attachment of DB2 to other subsystems (CICS, IMS/TM, or TSO). SSAS is also responsible for all logging activities (physical logging, log archival, and BSDS). DSNMSTR is the default name for this address space. (The address spaces may have been renamed at your shop.) DSNMSTR is the started task that contains the DB2 log. The log should be monitored regularly for messages indicating the errors or problems with DB2. Products are available that monitor the log for problems and trigger an event to contact the DBA or systems programmer when a problem is found.
The DBAS, or Database Services Address Space, provides the facility for the manipulation of DB2 data structures. The default name for this address space is DSNDBM1. This component of DB2 is responsible for the execution of SQL and the management of buffers, and it contains the core logic of the DBMS. Database services use system services and z/OS to handle the actual databases (tables, indexes, etc.) under the control of DB2. Although DBAS and SSAS operate in different address spaces, they are interdependent and work together as a formal subsystem of z/OS.
The DBAS can be further broken down into three components, each of which performs specific data-related tasks: the Relational Data System (RDS), the Data Manager (DM), and the Buffer Manager (BM). This is depicted in Figure 11.
The Buffer Manager handles the movement of data from disk to memory; the Data Manager handles the application of Stage 1 predicates and row-level operations on DB2 data; and the Relational Data System, or Relational Data Services, handles the application of Stage 2 predicates and set-level operations on DB2 data.
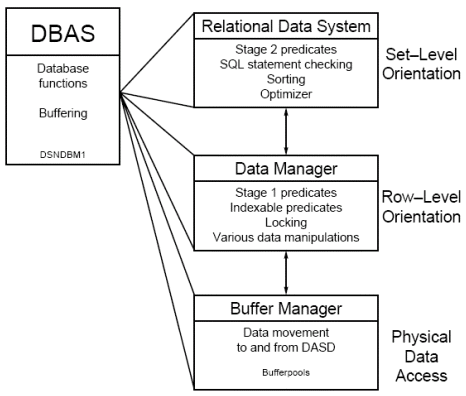
Figure 11: The components of the Database Services Address Space.
The next DB2 address space, DDFS, or Distributed Data Facility Services, is optional. DDFS, often simplified to DDF, is required only when you want distributed database functionality. If your shop must enable remote DB2 subsystems to query data between one another, the DDF address space must be activated. DDF services use VTAM or TCP/IP to establish connections and communicate with other DB2 subsystems using either DRDA or private protocols.
DB2 also requires an additional address space to handle locking. The IRLM, or Intersystem Resource Lock Manager, is responsible for the management of all DB2 locks (including deadlock detection). The default name of this address space is IRLMPROC.
Finally, DB2 uses additional address spaces to manage the execution of stored procedures and user-defined functions. These address spaces are known as the Stored Procedure Address Spaces, or SPAS. If you’re running DB2 V4, only one SPAS is available. For DB2 V5 and later releases, however, if you’re using the z/OS Workload Manager (WLM), you can define multiple address spaces for stored procedures. Indeed, as of DB2 V8, WLM-defined is the only approved method for new stored procedures. Pre-existing stored procedure will continue to run in a non-WLM-defined SPAS under DB2 V8. Of course, if the stored procedure is dropped and re-created it must use the WLM. The non-WLM-defined SPAS is being phased out and will be completely removed in a future version of DB2.
So, at a high level, DB2 uses five address spaces to handle all DB2 functionality. DB2 also communicates with allied agents, like CICS, IMS/TM, and TSO. And database services uses the VSAM Media Manager to actually read data. A summary of the DB2 address spaces and the functionality they perform is provided in Figure 12.
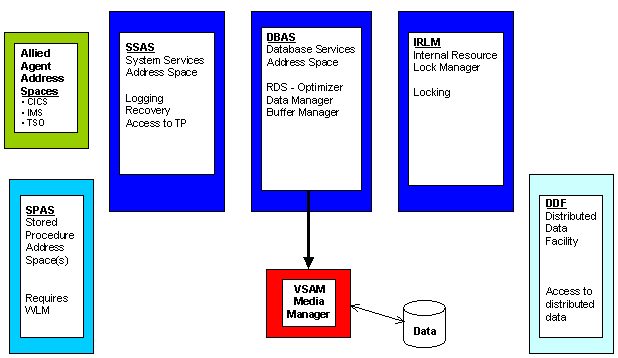
Figure 12: The DB2 address spaces.
Database Services
Recall that the DBAS is composed of three distinct elements. Each component passes the SQL statement to the next component, and when results are returned, each component passes the results back. The operations performed by the components of the DBAS as an SQL statement progresses on its way toward execution are discussed next.
The RDS is the component that gives DB2 its set orientation. When an SQL statement requesting a set of columns and rows is passed to the RDS, the RDS determines the best mechanism for satisfying the request. Note that the RDS can parse an SQL statement and determine its needs. These needs, basically, can be any of the features supported by a relational database (such as selection, projection, or join).
When the RDS receives a SQL statement, it performs the following procedures:
- Checks authorization
- Resolves data element names into internal identifiers
- Checks the syntax of the SQL statement
- Optimizes the SQL statement and generates an access path
The RDS then passes the optimized SQL statement to the Data Manager (DM) for further processing. The function of the DM is to lower the level of data that is being operated on. In other words, the DM is the DB2 component that analyzes rows (either table rows or index rows) of data. The DM analyzes the request for data and then calls the Buffer Manager (BM) to satisfy the request.
The Buffer Manager accesses data for other DB2 components. It uses pools of memory set aside for the storage of frequently accessed data to create an efficient data access environment.
When a request is passed to the BM, it must determine whether the data is in the bufferpool. If the data is present, the BM accesses the data and sends it to the DM. If the data is not in the bufferpool, it calls the VSAM Media Manager, which reads the data and sends it back to the BM, which in turn sends the data back to the DM.
The DM receives the data passed to it by the BM and applies as many predicates as possible to reduce the answer set. Only Stage 1 predicates are applied in the DM.
Finally, the RDS receives the data from the DM. All Stage 2 predicates are applied, the necessary sorting is performed, and the results are returned to the requester.
Now that you have learned about these components of DB2, you should be able to understand how this information can be helpful in developing a DB2 application. For example, consider Stage 1 and Stage 2 predicates. Now you can understand more easily that Stage 1 predicates are more efficient than Stage 2 predicates because you know that they are evaluated earlier in the process (in the DM instead of the RDS) and thereby avoid the overhead associated with the passing of additional data from one component to another.
Summary
This article delivers a brief introduction to the guts of DB2. Herein we have learned about the internal composition of DB2 objects and how data is stored. Additionally, we examined each of the address spaces that comprise a DB2 subsystem and learned the purpose of each. This basic DB2 architectural information will help you to better understand the internals of DB2 as you build efficient DB2 databases and applications.
--
Craig Mullins is an independent consultant and president of Mullins Consulting, Inc. Craig has extensive experience in the field of database management having worked as an application developer, a DBA, and an instructor with multiple database management systems including DB2, Sybase, and SQL Server. Craig is also the author of the DB2 Developer’s Guide, the industry-leading book on DB2 for z/OS, and Database Administration: Practices and Procedures, the industry’s only book on heterogeneous DBA procedures. You can contact Craig via his web site at http://www.craigsmullins.com.
|

